Insegnare a un Dinosauro a Saltare: Rust, WebAssembly ed Evoluzione Neurale
· 10m ·

Introduzione
Quello che è iniziato come un leggero e giocoso esperimento di programmazione si è rapidamente trasformato in un viaggio tecnico immersivo e multiforme, profondamente radicato nei domini dell’evoluzione neurale, della fisica di gioco in tempo reale e delle tecniche di simulazione basate su browser. Inizialmente, l’obiettivo era intenzionalmente semplice: replicare il noto gioco offline “Chrome Dino” — quello che ti intrattiene quando la tua connessione internet cade — utilizzando uno stack tecnologico web contemporaneo e ad alte prestazioni.
L’intento era utilizzare il progetto come trampolino di lancio per acquisire maggiore familiarità con Rust e WebAssembly, e magari divertirsi un po’ lungo il percorso. Tuttavia, approfondendo, l’ambito si è espanso considerevolmente. Ogni strato di complessità ha introdotto nuove opportunità di apprendimento, spingendo i confini di ciò che inizialmente pensavo avrei affrontato. Questo ha significato integrare simulazioni fisiche, logica decisionale basata sul tempo, interoperabilità tra linguaggi e, infine, tecniche di IA neuroispirate.
La svolta — e ciò che ha guidato l’evoluzione del progetto — è stata questa: non volevo solo controllare il dinosauro. Volevo progettare un sistema in cui il dinosauro potesse capire come giocare da solo — sviluppare un comportamento non attraverso istruzioni esplicite, ma imparando dal suo ambiente. Quel semplice cambiamento ha trasformato un clone in un sistema vivente ed evolutivo, capace di adattarsi ai cambiamenti nel suo ambiente.
Rust ha fatto da spina dorsale per la logica di simulazione, fornendo una sicurezza della memoria e prestazioni senza pari. WebAssembly ha colmato il divario con il browser, consentendo un’esecuzione a velocità nativa. Sul frontend, TypeScript e HTML5 Canvas hanno offerto un’interfaccia visiva reattiva dove il comportamento poteva essere osservato in tempo reale. Il risultato è stato una simulazione completamente interattiva e in tempo reale in cui il comportamento intelligente poteva emergere organicamente da una combinazione di regole semplici e pressione selettiva.
Questa è la storia di come sono passato da poche righe di codice a una simulazione evolutiva completa che esegue migliaia di agenti neurali indipendenti. Lungo il percorso, ho dovuto affrontare problemi di progettazione del sistema, rendering in tempo reale, debug di sistemi di apprendimento black-box e scalabilità fino a parallelismo massiccio — tutto all’interno di una scheda del browser. Questo viaggio non solo ha approfondito la mia comprensione di Rust, WebAssembly e reti neurali, ma mi ha anche portato ad apprezzare l’eleganza dell’apprendimento evolutivo e l’importanza di una visualizzazione chiara quando si lavora con sistemi adattivi complessi.
Fase 1: Costruire il Loop di Gioco
Il primo traguardo è stato stabilire le meccaniche di base del gioco: un runner a scorrimento laterale continuo in cui il personaggio controllato dal giocatore — un rettangolo verde che rappresenta il dinosauro — dovrebbe saltare sopra gli ostacoli.
La gravità è stata simulata con accelerazione verticale, e ostacoli rettangolari si muovevano da destra a sinistra. Se il dinosauro ne colpiva uno, il mondo si resettava. Questa logica è stata implementata interamente in Rust, poi compilata in WebAssembly usando wasm-pack. Questa configurazione iniziale mi ha permesso di definire un ambiente chiaro e deterministico con fisica semplice.
Il frontend è stato costruito usando TypeScript, e un loop di gioco che funzionava a 60 FPS aggiornava e renderizzava il mondo. Ho mantenuto le cose minimali in questa fase, concentrandomi sulla costruzione di un nucleo di simulazione stabile e un ciclo di feedback visivo. Il gioco si renderizzava direttamente su un Canvas HTML5, con ogni frame che rifletteva le posizioni aggiornate per il dino e gli ostacoli in arrivo. Ha fornito un ciclo di feedback rapido per testare la correttezza fisica del mio motore.
A questo punto, l’interazione dell’utente era l’unico input. Il dinosauro saltava solo se sollecitato tramite un evento mouse. Era un clone divertente, ma privo di intelligenza. Il passo logico successivo era dare al dino la capacità di agire senza intervento umano — percepire, decidere e agire.
Fase 2: Implementare una Rete Neurale di Base
Per far agire il dinosauro in modo autonomo, ho creato una rete neurale feedforward minima da zero in Rust.
La struttura della rete era semplice ma abbastanza potente da consentire un processo decisionale semplice:
- Input (3):
- Distanza dal prossimo ostacolo
- Velocità relativa degli ostacoli (derivata dal punteggio)
- Punteggio attuale (normalizzato)
- Output (1): un valore tra 0 e 1, che rappresenta una decisione di saltare
Ho usato una funzione sigmoidea per l’attivazione. Ad ogni dinosauro è stato assegnato un insieme unico di pesi e un bias. Il processo decisionale è stato codificato come segue: se l’output superava 0.6, e il dinosauro era a terra e l’ostacolo era sufficientemente vicino, avrebbe saltato. La logica appariva così:
if dino.on_ground && output > 0.6 {
dino.velocity_y = MAX_JUMP_FORCE;
dino.on_ground = false;
}
La maggior parte dei dinosauri falliva ancora — comprensibilmente, poiché avevano pesi casuali e nessun meccanismo di addestramento. Ma questa configurazione ha dato loro la capacità di prendere decisioni basate sull’input ambientale, che era la base per l’apprendimento.
Fase 3: Evoluzione Attraverso la Mutazione
Per facilitare l’apprendimento, ho implementato un algoritmo evolutivo ispirato agli algoritmi genetici e alla selezione naturale:
- Mantenere l’individuo con le migliori prestazioni come seme per la generazione successiva
- Generare una nuova popolazione mutando questo cervello migliore usando rumore gaussiano
fn evolve(&mut self) {
web_sys::console::log_1(&"🦀: 🌱 Evolving!".into());
let best = self.brains[self.best_index].clone();
self.fitness_history.push(best.fitness);
let seed_base = (self.generation as u64) * 1000;
let mut new_brains = vec![best.clone()];
for i in 1..POPULATION_SIZE {
new_brains.push(best.mutate(0.4, seed_base + (i as u64)));
}
self.brains = new_brains;
//...
self.generation += 1;
}
Il ciclo di simulazione si sarebbe riavviato automaticamente una volta che tutti i dinosauri fossero morti. Nel tempo, alcune reti hanno iniziato a mostrare strategie di sopravvivenza: tempismo migliorato, migliore anticipazione e sopravvivenza più lunga.
Questa fase ha trasformato la simulazione in un sistema di apprendimento auto-migliorante. Le prestazioni sono costantemente migliorate attraverso le generazioni, e l’ecosistema neurale è diventato sempre più diversificato. I dinosauri non venivano programmati per avere successo — stavano scoprendo, attraverso tentativi ed errori, cosa funzionava.
Fase 4: Aggiungere Strumenti di Debug Visivo
Sebbene il dino stesse ora evolvendo, non potevo interpretare facilmente il processo di apprendimento o la logica decisionale. Quindi ho aggiunto strumenti visivi per aiutare il debug e monitorare i cervelli dei migliori performer.
<body>
<canvas id="main" width="600" height="120"></canvas>
<canvas id="fitness" width="600" height="100" style="margin-top: 1rem;"></canvas>
<canvas id="weightsCanvas" width="600" height="100" style="margin-top: 1rem;"></canvas>
<canvas id="neuralNet" width="600" height="300" style="margin-top: 1rem;"></canvas>
<!-- ... -->
</body>
Questi strumenti includevano:
- Un grafico della storia di fitness per visualizzare i progressi a lungo termine attraverso le generazioni, aggiornato in tempo reale
- Una mappa di calore dei pesi codificata a colori, che consentiva l’ispezione visiva di come i singoli pesi sinaptici evolvevano
- Una visualizzazione della rete neurale in tempo reale, dove nodi (neuroni) e connessioni venivano disegnati nel browser. Il colore e lo spessore di ogni connessione rappresentavano il suo peso, e ogni neurone mostrava il suo valore di attivazione
Questa strumentazione mi ha permesso di acquisire una comprensione più profonda di ciò che stavano facendo le reti con le migliori prestazioni. Ha anche fornito utili informazioni per la messa a punto dei tassi di mutazione e di altri iperparametri.
Fase 5: Architetture Più Profonde e Cervelli Più Intelligenti
Per aumentare la potenza rappresentativa della rete, ho aggiunto uno strato nascosto con 9 neuroni, trasformando l’architettura in 3 → 9 → 1. Questo cambiamento ha introdotto non linearità nel sistema e ha permesso confini decisionali più complessi.
Ho implementato tutti i calcoli di forward-pass manualmente in Rust: moltiplicazione di matrici, aggiunta di bias e attivazione sigmoidea. Questo ha permesso un controllo e una visibilità completi su come i dati fluivano attraverso la rete, e ha mantenuto le prestazioni entro limiti accettabili per la simulazione su larga scala.
Il visualizzatore della rete è stato aggiornato per riflettere questo cambiamento architettonico. Ora, le attivazioni si propagavano dai neuroni di input a quelli nascosti fino all’output, e le modifiche nei pesi potevano essere osservate nel tempo. Questo ha reso possibile vedere non solo il comportamento, ma anche la struttura di ragionamento sottostante che ha portato a quel comportamento.
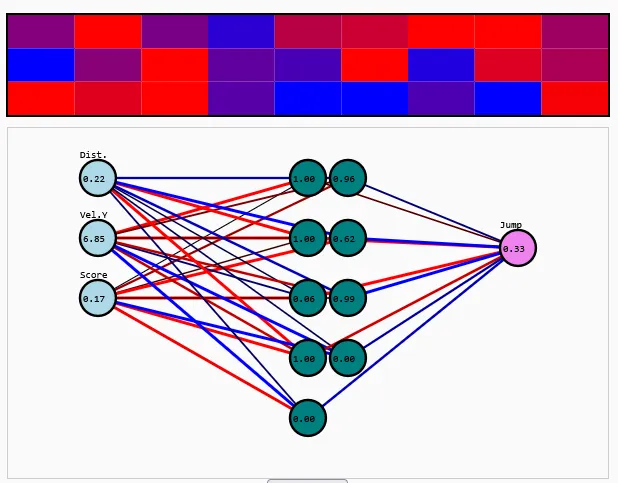
Come previsto, la rete ha iniziato a mostrare una migliore adattabilità. Poteva ora apprendere distinzioni più sottili, come quando ritardare un salto o come rispondere a ostacoli più veloci.
Inaspettatamente, ho notato che la maggior parte dei neuroni nascosti alla fine si atrofizzava — i loro valori di attivazione si appiattivano a zero. In risposta, ho ridotto lo strato nascosto a 3 neuroni e ho ancora ottenuto risultati di apprendimento comparabili. Questa è stata una lezione preziosa sulla semplicità e parsimonia del modello.
Fase 6: Scalare la Simulazione
Con le ottimizzazioni delle prestazioni in atto, ho scalato la simulazione per gestire migliaia di agenti in parallelo. Inizialmente ho usato 16 agenti, poi sono passato a 256, e infine a 5000. Ogni agente aveva il suo mondo di simulazione isolato. La versione rilasciata è limitata a 200 per consentire ai client di fascia bassa di eseguire la simulazione senza lag.
Inizialmente, il rendering simultaneo di migliaia di agenti dino era computazionalmente costoso, quindi solo l’agente con le migliori prestazioni veniva visualizzato in dettaglio. Gli altri esistevano puramente in simulazione. Ma in seguito, ho aggiunto la visualizzazione completa dello sciame per osservare tutti gli agenti che tentavano di avere successo in tempo reale.
Grazie all’efficienza computazionale di Rust e al modello di esecuzione di WebAssembly, sono stato in grado di eseguire migliaia di aggiornamenti al secondo all’interno di un browser web. Questo ha permesso una convergenza più rapida nell’apprendimento evolutivo e ha migliorato la reattività complessiva del sistema.
Fase 7: Distribuzione e Accesso Aperto
Ho distribuito il progetto utilizzando GitHub Actions, che ha compilato il codice Rust, ha impacchettato gli asset frontend e ha pubblicato tutto su GitHub Pages. Il risultato finale è un sito completamente statico che non richiede backend o server. Gli utenti possono caricarlo e iniziare a simulare direttamente nel browser.
Questo lo rende perfetto per l’educazione, la sperimentazione e la condivisione. L’intero stack funziona localmente, rendendo la simulazione completamente riproducibile, e il codice sorgente è aperto per essere esplorato e modificato da altri.
Lezioni Apprese
- Costruire reti neurali da zero approfondisce l’intuizione su come funzionano i sistemi di apprendimento
- La visualizzazione in tempo reale è cruciale per comprendere e debuggare il comportamento adattivo
- Le strategie evolutive possono produrre soluzioni sorprendentemente robuste anche in ambienti vincolati
- Rust + WebAssembly è uno stack potente per simulazioni ad alte prestazioni nel browser
- La semplicità nel design può portare a complessità emergente dati i giusti cicli di feedback
Lavori Futuri
Ci sono molte direzioni entusiasmanti da esplorare:
- Aggiungere neuroni di output aggiuntivi per supportare azioni complesse come la forza di salto variabile
- Introdurre funzioni di attivazione alternative (ad es., tanh, ReLU)
- Memorizzare e ricaricare reti di successo per consentire un miglioramento continuo attraverso le sessioni
- Aggiungere strumenti per l’utente per ispezionare e confrontare diversi cervelli
- Creare progressione di livello o sfide di apprendimento curricolare
Provalo Tu Stesso
Questa dimostrazione interattiva consente l’osservazione in tempo reale di un sistema neuroevolutivo implementato in Rust e WebAssembly. L’ambiente è completamente deterministico e renderizzato attraverso HTML5 Canvas, offrendo una visione diretta del comportamento di agenti autonomi addestrati tramite meccanismi di apprendimento biologicamente ispirati. La visualizzazione include attivazioni live, dinamiche dei pesi e simulazione multi-agente, rendendolo adatto sia per l’esplorazione della ricerca che per scopi didattici.
Conclusione
Questo progetto è iniziato come un esperimento personale per esplorare Rust e WebAssembly, ma è cresciuto fino a diventare un sistema di apprendimento completo alimentato da semplici reti neurali e pressione evolutiva. È stata un’opportunità per scoprire come un comportamento significativo possa emergere da casualità, feedback e pressione selettiva.
C’è qualcosa di poetico nel guardare un dinosauro quadrato imparare a saltare sopra gli ostacoli — non perché gli è stato detto come fare, ma perché ha provato, fallito e migliorato. Questa è l’essenza dell’apprendimento — ed è incredibilmente soddisfacente da osservare.
Spero che questo ti ispiri a costruire i tuoi esperimenti. Con gli strumenti giusti, anche un semplice gioco può diventare un campo di gioco per l’evoluzione e l’intelligenza.
Grazie per aver seguito — e che il tuo prossimo progetto di IA sia altrettanto divertente, strano e gratificante. 🦕